Hledáte jednoduchý způsob, jak z PDF vytáhnout text? Nechcete trávit hodiny přepisováním textů ze skenů nebo z obrázků, fotek? S technologií OCR (Optical Character Recognition) je konec těchto starostí! Podívejte se, jak snadno převést obrázky a skeny na editovatelný text. A ušetřit tak cenný čas i energii.
Co je technologie OCR a k čemu slouží
Nejprve si objasněme, co je OCR PDF. Jednoduše řečeno jde o rozpoznání textu z obrázku. OCR (Optical Character Recognition = optické rozpoznávání znaků) dokáže identifikovat text v digitálních obrázcích a převést jej na editovatelný formát.
Díky tomu nemusíte ručně přepisovat obsah dokumentů, ale můžete s ním ihned pracovat jako s běžným digitálním textem. A pomocí softwaru na úpravu PDF můžete text v obrázcích rovnou i editovat, jakkoliv právě potřebujete.
Moderní OCR systémy dosahují vysoké přesnosti a dokáží rozpoznat různé styly písma, jazyky, znaky, mnohdy i ručně napsaný text. Ano, s OCR se dají ručně psané poznámky pohodlně digitalizovat a následně třeba převést do MS Office.
Jak se OCR používá
Základním předpokladem využití je kvalitní vstupní materiál. dokumenty by měly být oskenované v dostatečném rozlišení a kontrastu, aby algoritmus mohl správně rozpoznat jednotlivé znaky.
Máte-li splněnu tuto podmínku, pak vám OCR nabídne široké spektrum využití. Ukažme si to nejčastější:
- digitalizace dokumentů – převod papírových dokumentů do digitální podoby, abyste usnadnili archivaci, sdílení a vyhledávání
- automatizace procesů – OCR pomáhá zpracovávat dokumenty bez nutnosti lidského zásahu
- zpracování formulářů – automatické zpracování papírových formulářů, byste ušetřili nejen čas, ale i chybovost při ručním zadávání dat
- práce s naskenovanými PDF – OCR přemění naskenované PDF soubory na plně prohledávatelné dokumenty, abyste v nich mohli vyhledávat, kopírovat a upravovat text.
- překládání textů – ve spojení s nástroji pro překlad lze OCR použít k překladu textu z fotografií nebo naskenovaných dokumentů
Kde se s OCR setkáte
S technologií OCR se dnes setkáváme častěji, než si uvědomujeme. V kancelářském prostředí ji najdeme v multifunkčních tiskárnách, systémech pro správu dokumentů a účetním softwaru pro zpracování faktur. Na mobilních zařízeních využíváme aplikace jako Google Lens nebo funkci živého překladu v Google Překladači.
Ve veřejném prostoru slouží OCR k rozpoznávání registračních značek, ověřování údajů v bankomatech nebo třídění poštovních zásilek. Akademické instituce ji používají k digitalizaci knihoven a archivů. V podnikatelské sféře pomáhá při automatizovaném zpracování dokumentů, ověřování dokladů a k analýze kontaktních údajů pro CRM systémy. V současnosti už nechybí ani v některých automobilech.
Jak z PDF vytáhnout text? Nejlepší výsledky dodá specializovaný software
Přestože se setkáte s online převaděči obrázků na text (s OCR online), výsledky bývají u pestřejších obrázků neuspokojivé. Využít se online převaděče dají jen pro rozpoznání jednoduchých textů ve skenech z bílého papíru, a to ještě s nepřesnými výsledky. K těm spolehlivějším patří onlineocr.net.
Stojíte-li o profesionální a bezchybné OCR, vždycky se vyplatí pořídit si specializovaný software. Na trhu potkáte spoustu nabídek, od velmi drahého Adobe, až po nízkonákladový PDF-XChange. V obou programech najdete spolehlivé OCR s vysokou přesností rozpoznávání.
Použití OCR je snadné, ukažme si to na příkladu obrázku (fotky). Stejný obrázek jsme zadali k rozpoznání i v online převodnících, ale dobrý výsledek jsme nikde neobdrželi. Naopak v PDF-XChange Editoru si lokální OCR s tímto úkolem poradí bez jediného zádrhele.
Jak vytáhnout text z obrázku v PDF-XChange Editoru
Postup je snadný, ale vyžaduje několik kroků:
1. Nejprve v PDF-XChange Editoru otevřete kýžený obrázek. Jděte přes nabídku „Soubor“ – „Nový dokument“ – „Z obrázků“ (případně „Ze skeneru“ – až budete pracovat se skeny).
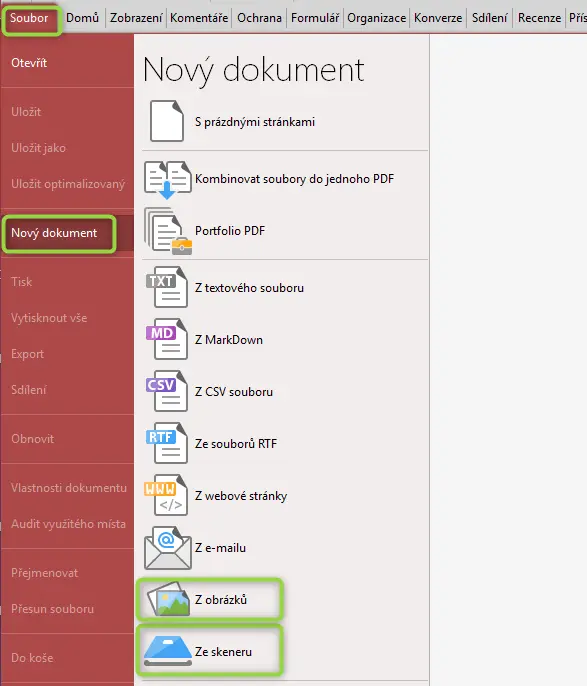
2. Otevře se dialogové okno, v něm klikněte na „Přidat soubory“, pokud chcete otevřít jen jeden obrázek nebo chcete vybrat konkrétní soubory. Otevře se průzkumník souborů a v něm vyberete obrázek, s nímž chcete pracovat.
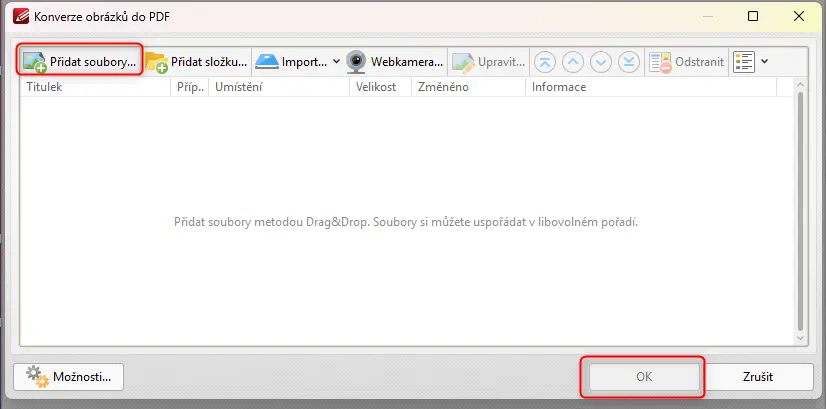
Je tu ale i možnost „Přidat složku“ nebo importovat, případně pořídit obrázek webkamerou. Jakmile jste vybrali, schvalte výběr tlačítkem OK.
3. Obrázek se v programu otevře a vy pak na horní liště klekněte na záložku „Konverze“, v ní vyberte „OCR“.

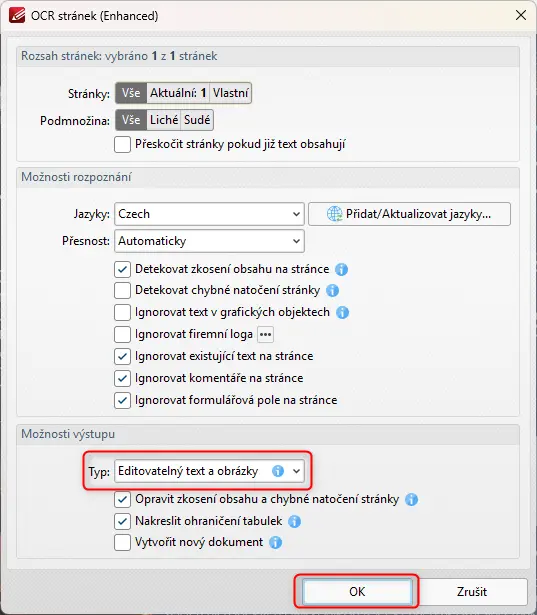
4. Tím se otevře dialogové okno, ve němž si nastavíte detaily rozpoznání textu. Program automaticky nastavuje to nejlepší, co v dané situaci algoritmus uzná za vhodné, ale nastavení můžete změnit.
5. OCR bude chvilku pracovat, proces zpracování se vám ukáže na samostatné liště.
6. A je hotovo. Všechna místa, kde byl na obrázku text, se přemění na textová pole. Upravovat, kopírovat a vkládat jinam nebo přenášet po ploše obrázku je budete po kliknutí na záložku „Domů“ a v ní na „Upravit text“.
Původní obsah pod textovou vrstvou se (v této variantě) odstraní, aby nepřekážel v další práci.

Všimněte si na fotkách a přiloženém videu, že OCR, které lze pořídit spolu s nízkonákladovým PDF-XChange Editorem, převedlo do běžného textu dokonce i logo příspěvkové organizace.
Celý postup jsme také natočili jako jednoduché návodové video.
Stojíte jen o samotný text? Nebo chcete vyčistit skeny?
Jestliže chcete z obrázku jen extrahovat text, bez podkladu, pak v dialogovém okně u OCR vyberete jinou možnost. Namísto „Editovatelný text a obrázky“ zvolte „Obsah stránky“. Každá z možností je v dialogovém okně detailně popsaná, aby se dalo hned vybrat, co lépe vyhovuje očekávanému výsledku.
Návod na postup v Adobe Acrobat vynecháváme. Jednak jde o příliš nákladný software, jednak je rozepsaný na stránkách podpory Adobe.
Staňte se mistry v ovládání PDF souborů: